
Batch Submission of Data - Overview
On this page:
Batch Data Submission Overview
Batch submission is loading a batch of data records all at the same time.
Understanding of Batch Submission of Data - Training Video
The advantages of batch loading data are:
- It allows for mass entry of data
- Processing of valid data happens without human interaction
- The system will notify the user when the process is complete
- Provides the user with results detailing the outcome
There are several steps used to submit data from a text file into the AQS database, those steps depend on the type of data involved. The big picture process involves:
- Transfer - move a data file to the EPA using the Exchange network (node or ENSC)
- Load - Run a batch process to Load this data into the AQS database
- Post - For raw data only, after reviewing the results of load, flag data as production-ready (available to all)
- The process described here is for completing a batch submission using AQS interactively. An alternative is to use an organization's node on the Exchange Network. For instructions on how to do that, see the AQS Flow Configuration Document on the Exchange Network website.
Formats
There are two data formats that may be submitted:
- AQS transactions - the AQS pipe delimited transaction format introduced in 2001
- XML - structured text data with <tags>
The format used will depend on what data acquisition system and/or analytical labs is available to the user. The vast majority of users take advantage of the AQS transaction format.
Data Compatible with Batch
Not all data in AQS can be loaded via the batch process. Here is a list of the types of data that can be loaded via batch:
- Site data
- Monitor data
- Raw (sample) data
- Quality Assurance data
Here are the types of data that cannot be loaded via batch:
- Comments (describing sites, monitors, audits, events, etc.)
- Exceptional event definitions, data associations, and concurrence (for EPA staff only)
Batch Data Submissions Flowchart
The following explains the data flow to AQS.
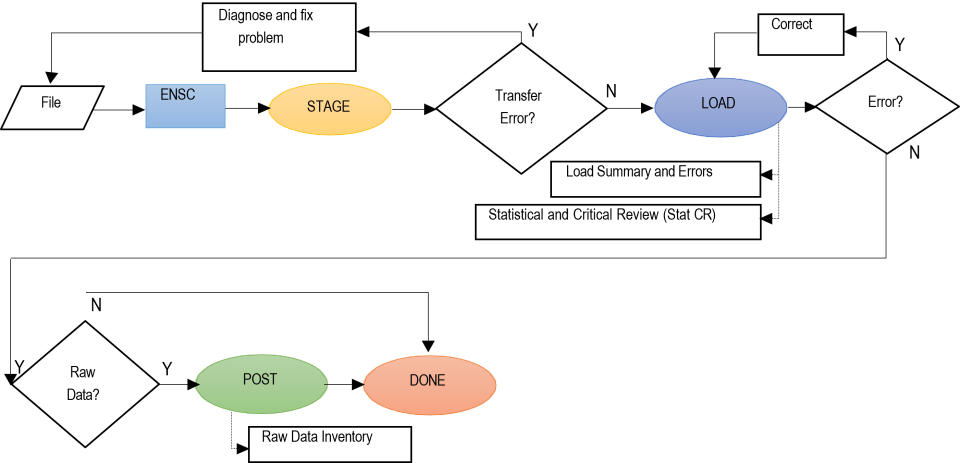
Step 1 (File):
Create file of ambient air data. Valid options are either text files (.txt) using the familiar delimited "Data Input Formats" or XML files (.xml) using the AQS Schema.
[Note] Data input formats can be found in here:
https://aqs.epa.gov/aqsweb/documents/TransactionFormats.html
Step 2 (ENSC):
Transfer the file to AQS using the Exchange Network Services Center (ENSC).
There are two process control options from the ENSC:
- Option 1 - Manually process: logon to AQS, choose the Screening Group, and proceed to the Batch Screen.
- Option 2 - Automatically process: use the ENSC exclusively, bypass AQS and process all data via the ENSC.
Step 3 (STAGE):
Processes the file into AQS.
Step 4 (LOAD):
For anything other than Raw Data (i.e. sample measurements) if there were no errors in the file the processing is complete. For Raw Data, the LOAD step also performs STAT/CR (Statistical and Critical Review).
Step 5 (POST):
Moves data from where it can only be seen by members of the relative screening group to where it can be seen by any AQS user (and any EPA web application, and thus the public). It also updates all of the summary values (e.g., NAAQS durations, Daily, Annual, and Design Value if applicable) that the raw data contributes to. This also means that it will be used by EPA in any calculations c(completeness, compliance, etc.).